

Suponha que você queira raspar informações da página de preços dos sites concorrentes. O que você fará? Copiar e colar ou inserir dados manualmente é muito lento, consome tempo e propenso a erros. Você pode automatizá-lo facilmente usando Python.
Vamos ver como raspar páginas da web usando Python neste tutorial.
Quais são as diferentes bibliotecas de web scraping em Python? Python é popular para web scraping devido à abundância de bibliotecas de terceiros que podem raspar estruturas HTML complexas, analisar texto e interagir com formulários HTML. Aqui, listamos algumas das principais bibliotecas de web scraping em Python.
- Urllib3 é uma poderosa biblioteca de cliente HTTP para Python. Isso facilita a realização de solicitações HTTP programaticamente. Ele lida com cabeçalhos HTTP, tentativas, redirecionamentos e outros detalhes de baixo nível, tornando-o uma excelente biblioteca para web scraping. Ele também oferece suporte à verificação SSL, pooling de conexões e proxy.
- BeautifulSoup permite analisar documentos HTML e XML. Usando a API, você pode navegar facilmente pela árvore de documentos HTML e extrair tags, títulos de meta, atributos, texto e outros conteúdos. BeautifulSoup também é conhecido por seu robusto tratamento de erros.
- MechanicalSoup automatiza a interação entre um navegador da web e um site de forma eficiente. Ele fornece uma API de alto nível para web scraping que simula o comportamento humano. Com o MechanicalSoup, você pode interagir com formulários HTML, clicar em botões e interagir com elementos como um usuário real.
- Requests é uma biblioteca Python simples, mas poderosa, para fazer solicitações HTTP. É projetado para ser fácil de usar e intuitivo, com uma API limpa e consistente. Com o Requests, você pode enviar facilmente solicitações GET e POST, e lidar com cookies, autenticação e outros recursos HTTP. Também é amplamente utilizado em web scraping devido à sua simplicidade e facilidade de uso.
- Selenium permite automatizar navegadores da web como Chrome, Firefox e Safari e simular a interação humana com sites. Você pode clicar em botões, preencher formulários, rolar páginas e realizar outras ações. Também é usado para testar aplicativos da web e automatizar tarefas repetitivas.
- Pandas permite armazenar e manipular dados em vários formatos, incluindo CSV, Excel, JSON e bancos de dados SQL. Usando o Pandas, você pode limpar, transformar e analisar facilmente dados extraídos de sites.
Extraia texto de qualquer página da web em apenas um clique. Acesse o raspador de sites Nanonets, adicione a URL e clique em “Raspar” e baixe o texto da página da web como um arquivo instantaneamente.
Como raspar dados de sites usando Python?
Vamos dar uma olhada no processo passo a passo de usar Python para raspar dados de sites.
Passo 1: Escolha o site e a URL da página da web O primeiro passo é selecionar o site que você deseja raspar. Para este tutorial específico, vamos raspar https://www.imdb.com/. Tentaremos extrair dados sobre os filmes mais bem avaliados no site.
Passo 2: Inspeção do site Agora, o próximo passo é entender a estrutura do site. Entenda quais são os atributos dos elementos que são de seu interesse. Clique com o botão direito do mouse no site para selecionar “Inspecionar”. Isso abrirá o código HTML. Use a ferramenta de inspeção para ver o nome de todos os elementos a serem usados no código.
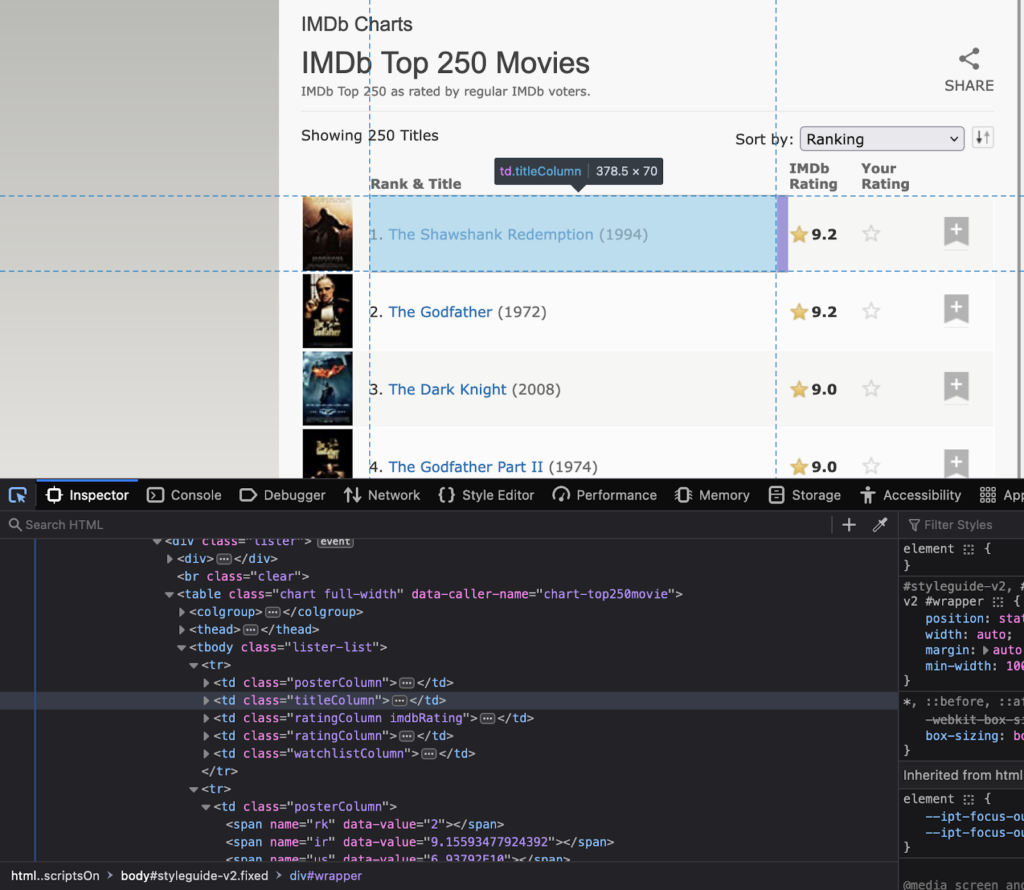
Observe os nomes de classe e ids desses elementos, pois serão usados no código Python.
Passo 3: Instalando as bibliotecas importantes Como discutido anteriormente, Python tem várias bibliotecas de web scraping. Hoje, usaremos as seguintes bibliotecas:
- requests – para fazer solicitações HTTP ao site
- BeautifulSoup – para analisar o código HTML
- pandas – para armazenar os dados raspados em um dataframe
- time – para adicionar um atraso entre as solicitações para evitar sobrecarregar o site com solicitações Instale as bibliotecas usando o seguinte comando:
pip install requests beautifulsoup4 pandas time
Passo 4: Escrever o código Python Agora, é hora de escrever o código Python principal. O código realizará as seguintes etapas:
- Usando requests para enviar uma solicitação HTTP GET
- Usando BeautifulSoup para analisar o código HTML
- Extraindo os dados necessários do código HTML
- Armazenar as informações em um dataframe pandas
- Adicionar um atraso entre as solicitações para evitar sobrecarregar o site com solicitações Aqui está o código Python para raspar os filmes mais bem avaliados do IMDb:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# URL do site para raspar
url = “https://www.imdb.com/chart/top”
# Enviar uma solicitação HTTP GET para o site
response = requests.get(url)
# Analisar o código HTML usando BeautifulSoup
soup = BeautifulSoup(response.content, ‘html.parser’)
# Extrair as informações relevantes do código HTML
filmes = []
for linha in soup.select(‘tbody.lister-list tr’):
titulo = linha.find(‘td’, class_=’titleColumn’).find(‘a’).get_text()
ano = linha.find(‘td’, class_=’titleColumn’).find(‘span’, class_=’secondaryInfo’).get_text()[1:-1]
classificacao = linha.find(‘td’, class_=’ratingColumn imdbRating’).find(‘strong’).get_text()
filmes.append([titulo, ano, classificacao])
# Armazenar as informações em um dataframe pandas
df = pd.DataFrame(filmes, columns=[‘Título’, ‘Ano’, ‘Classificação’])
# Adicionar um atraso entre as solicitações para evitar sobrecarregar o site com solicitações
time.sleep(1)
Passo 5: Exportar os dados extraídos Agora, vamos exportar os dados como um arquivo CSV. Usaremos a biblioteca pandas.
# Exportar os dados para um arquivo CSV
df.to_csv(‘filmes-mais-bem-avaliados.csv’, index=False)
Passo 6: Verificar os dados extraídos
Abra o arquivo CSV para verificar se os dados foram raspados e armazenados com sucesso.
Esperamos que este tutorial o ajude a extrair dados das páginas da web facilmente.

Como Analisar Texto Do Site?
Você pode analisar facilmente o texto do site usando BeautifulSoup ou lxml. Aqui estão os passos envolvidos junto com o código.
- Enviaremos uma solicitação HTTP para a URL e obteremos o conteúdo HTML da página.
- Assim que tivermos a estrutura HTML, usaremos o método find() do BeautifulSoup para localizar
- uma tag HTML específica ou um atributo.
- E então extrair o conteúdo de texto com o atributo text.
Aqui está um código de como analisar texto de um site usando BeautifulSoup:
import requests
from bs4 import BeautifulSoup
# Envie uma solicitação HTTP para a URL da página da web que você deseja acessar
resposta = requests.get(“https://www.example.com”)
# Analise o conteúdo HTML usando BeautifulSoup
soup = BeautifulSoup(resposta.content, “html.parser”)
# Extraia o conteúdo de texto da página da web
texto = soup.get_text()
print(texto)

Como raspar formulários HTML usando Python?
Para raspar formulários HTML usando Python, você pode usar uma biblioteca como BeautifulSoup, lxml ou mechanize. Aqui estão os passos gerais:
- Envie uma solicitação HTTP para a URL da página da web com o formulário que você deseja raspar. O servidor responde à solicitação retornando o conteúdo HTML da página da web.
- Uma vez que você acessou o conteúdo HTML, você pode usar um analisador HTML para localizar o formulário que deseja raspar. Por exemplo, você pode usar o método find() do BeautifulSoup para localizar a tag do formulário.
- Depois de localizar o formulário, você pode extrair os campos de entrada e seus valores correspondentes usando o analisador HTML. Por exemplo, você pode usar o método find_all() do BeautifulSoup para localizar todas as tags de entrada dentro do formulário e, em seguida, extrair seus atributos de nome e valor.
- Você pode então usar esses dados para enviar o formulário ou realizar mais processamento de dados.
Aqui está um exemplo de como raspar um formulário HTML usando mechanize:
import mechanize
# Crie um objeto de navegador mechanize
navegador = mechanize.Browser()
# Envie uma solicitação HTTP para a URL da página da web com o formulário que você deseja raspar
navegador.open(“https://www.example.com/form”)
# Selecione o formulário a ser raspado
navegador.select_form(nr=0)
# Extraia os campos de entrada e seus valores correspondentes
for controle in navegador.form.controls:
print(controle.name, controle.value)
# Envie o formulário
navegador.submit()
Extraia texto de qualquer página da web com apenas um clique. Acesse o raspador de sites da Nanonets, adicione a URL e clique em “Raspar”, e baixe o texto da página da web como um arquivo instantaneamente.
Conclusão
Python se destaca como uma escolha excepcional para a extração de dados de sites em tempo real. Quer aprofundar ainda mais seu conhecimento? Confira nosso vídeo completo no link: https://developerflix.com/movie/introducao-ao-web-scraping-e-crawling/
- 0 Comments
- desenvolvimento
- seo
- tecnologia
- web scraping
